Matching in MineMatch and
LegendBurster:
Theory and Practice
Georeference
Online Limited
October, 2002
Abstract
This document presents the theory and the details of the matcher used in MineMatch and LegendBurster. The current version uses a qualitative notion of matching based on finding the least surprising match. The interpretation for the qualitative terms of uncertainty is defined. We explain how to interpret the output of MineMatch.
TABLE OF CONTENTS
Abstract................................................................................................................................................................................................................ 1
PART 1: Theory.................................................................................................................................................................................................... 3
Introduction...................................................................................................................................................................................................... 3
Instances, Models and Queries............................................................................................................................................................... 3
Describing Instances and Models........................................................................................................................................................ 4
Matching (Similarity Ranking) and Hierarchies......................................................................................................................... 5
Describing Instances.................................................................................................................................................................................... 8
Matching, Missing Values and the Homo-hierarchy................................................................................................................ 9
Model-Instance
matching..................................................................................................................................................................... 9
Instance-Instance
matching............................................................................................................................................................. 10
Model-Model
matching......................................................................................................................................................................... 11
Matching and the Semantic Network............................................................................................................................................. 11
Matching Examples...................................................................................................................................................................................... 13
Part 2: Practice............................................................................................................................................................................................. 16
Introduction.................................................................................................................................................................................................... 16
How Scores (Penalties and Rewards) are Calculated....................................................................................................... 16
Model to Instance
Comparing........................................................................................................................................................... 16
Model and Instance have the same attribute.......................................................................................................................................... 17
When Model and Instance have “disjoint” attributes........................................................................................................................... 18
Comparison at
Sub-Levels of Description.................................................................................................................................. 19
Match Types................................................................................................................................................................................................... 20
Matches.......................................................................................................................................................................................................... 20
Conflicts......................................................................................................................................................................................................... 20
Comparison
Examples............................................................................................................................................................................. 21
PART 1: Theory
Introduction
There are many mineral deposits in the world, and they can be grouped in various ways. Many groups of people have developed models of mineral deposits to which actual mineral deposits can be matched. One of the aims of MineMatch is to be able to find the closest model for a mineral deposit from a collection of models. The current version of MineMatch uses qualitative models. Such models specify what features of the mineral deposits we expect to be there, and which we expect to be absent. This expectation is in terms of a qualitative measure of surprise. This matching is a nontrivial problem because we allow for hierarchically structured models, hierarchically structured descriptions of mineral deposits, hierarchical relationships between attribute values, hierarchical relationships between attributes, and because we don’t require complete descriptions of the models or the mineral deposits.
A future version of MineMatch will allow for probabilistic information about how likely a particular feature is for a particular model. This will be useful when the model is more quantitative: for example, when the model or parts of it are the result of a neural network learning algorithm. We plan to be able to support a diversity of models.
Instances, Models and Queries
Models of any phenomenon or entity generally break down into two parts: a descriptive part which specifies the features of any instance which “fits” or “matches” the model, and an interpretive part which describes or interprets how instances which fit the model operate, or came into being. In geology the latter are commonly referred to as genetic models.
MineMatch concentrates on the first aspect of mineral deposit models: the description of their observable features. Descriptive models, also called “deposit types”, have historically proven much less changeable than genetic models.
Such descriptions are abstract, in that they are not descriptions of any single instance. As such, they are more akin to a query than to a specific description of an object.
LegendBurster, which is an information representation and querying system for Geographic Information Systems, represents its queries in exactly the same way as a MineMatch model.
For the rest of this document we will refer to particular mineral deposits as instances. An instance can be a mine, a prospect under evaluation or a mineral occurrence. MineMatch is able to compare instances to instances, instances to models or models to models.
Describing Instances and Models
We assume that both models and instances are described in terms of entities (e.g., a mineral assemblage, or a mineral), attributes (e.g., a mineral) and values (e.g., quartz). We don’t assume that an entity has a unique value for an attribute. For example, a mineral assemblage could contain many minerals. This document uses the term feature for an attribute-value pair.
A model specifies what would be expected to be in an instance that matches the model. It specifies what must be in the instance, what cannot be there and what we would expect to be there. By saying that we expect some feature, we mean that we would be surprised if it were absent.
Each feature of an instance is labeled as being present or absent. Present can also be interpreted as true and absence as false. For example, a particular alteration may have AlterationType acid-leaching present and AlterationType decarbonisation absent. For those features not described as being present or absent, there are three ways that we can interpret the missing information:
- Silence implies Absence: if a feature is not explicitly specified, then it is absent. This is used when we have a complete description of the instance.
- We can ignore extra features: we remain agnostic about whether the feature is present or absent. This assumes that if the person didn’t specify it, it could be present or absent; we don’t know.
- In between these two extremes, we can assume that if a feature is important and obvious, then it will be in the description. This is what we assume by default. Under this assumption we are less sure about a missing value for the feature than we are about a value that is explicitly mentioned.
The features of a model are labeled as:
- Always: This feature is always in any instance that matches the model. An instance for which this feature is known to be absent doesn’t match this model.
- Usually: This feature is usually present in an instance that matches the model. That is, we would be surprised if this feature were absent in an instance that matches the model.
- Sometimes: This feature is sometimes in an instance that matches the model: we would not be surprised if it were present or absent.
- Rarely: This feature is usually absent in an instance that matches the model. That is, we would be surprised if this feature were present in an instance that matches the model.
- Never: This feature is never present in any instance that matches the model. An instance for which this feature is known to be present doesn’t match this model.
When examining the similarity between objects or concepts, it is generally not helpful to give any single feature absolute influence over a similarity ranking measure. This would effectively eliminate a gradational scale of similarity measures - when the very concept of similarity implies a range of values. Consequently, despite the definitions above of “always” and “never”, conflicting features involving either of these expected frequencies may not prevent a pair of compared objects from scoring a relatively high similarity ranking. This is the best policy to adopt when undertaking similarity ranking exercises in the absence of specialist knowledge or requirements.
There are, however, times when exclusive forms of “always” and “never” are required - which have the effect of ensuring that an object without (or with) a particular feature will occur at the bottom of the similarity ranking, no matter what other matching features it has.
In MineMatch and LegendBurster we implement this requirement with the frequency “MustHave” instead of “always”, and “MustExclude” instead of “never”. They are defined below:
- Must Have: This feature must be present in any instance that is compared with the model. An instance for which this feature is known to be absent, or not mentioned, is effectively excluding from the similarity ranking exercise, and given the minimum similarity value.
- Must Exclude: This feature must be absent or not mentioned in any instance that is compared with the model. An instance for which this feature is known to be present is effectively excluding from the similarity ranking exercise, and given the minimum similarity value.
From the above definitions, it is clear that “MustHave” and “MustExclude” are implemented under the “Silence implies Absence” assumption.
There are two special values that can be selected for a model feature: <other values>, <any value>.
The feature [attribute, <other values>, frequency] specifies whether other values are allowed for the attribute. If the frequency is never, then obviously, no other values are allowed for the attribute. [As explained in Part 2 of this document, during any comparison exercise, extra penalties will be incurred against any instance which contains features whose values that do not match those of the model’s values. Alternatively, if the frequency is not never, then other values for this attribute are possible, and no extra penalties will be incurred.]
The feature [attribute, <any value>, frequency] specifies that any value is allowed for the attribute. [In such a situation, no rewards are given to an instance’s feature that matches the model feature.]
Matching (Similarity Ranking) and Hierarchies
The model that gives the best match to an instance is the one that induces the least surprise.
The simple model of surprise can be seen as a qualitative analogue of probability, namely the conditional probability of the instance given the model (how likely this model would have given rise to this instance). A surprise can be seen as an order-of-magnitude probability that the feature is absent. Always means the feature is present with probability one, usually means the feature is present with probability close to one, sometimes means a non-extreme probability, rarely means the feature is present with a low probability and never means a probability of zero that the feature is present. The sum of the surprises corresponds to the number of small probabilities that need to be multiplied together.
The simple view of surprises needs to be complicated in a few ways:
- We don’t want the empty model to be the best model. (Just as in probability theory where a model that specifies less is more likely). We use some rewards for matching. We don’t want to penalize a model because it specifies more detail; we would like to reward it for being predictive.
- The model features can be hierarchically specified, and the instances features can be hierarchically specified. Unfortunately, we can’t assume that the way the instance and the model are decomposed into hierarchies is the same. For example, an instance may be described in terms of zones, where each zone has its own features, but a model may have no zones. There are three hierarchical relationships that we need to consider:
- The value hierarchy, or the homo-hierarchy, is the hierarchy of values in a particular attribute domain. Each of the members of the homo-hierarchy is a kind of (AKO) the value that is its parent.
- The semantic network provides the hierarchy for the models or the instances. Whereas the value-hierarchy uses just the “AKO” attribute, the semantic network allows for arbitrary attributes. The semantic network is used for describing a model or instance in terms of multiple entities and describing these using various attributes. It is typically a hierarchy because the model or instance can contain different parts and these parts contain subparts. However, often the network is more tangled as there can be complex relationships between the parts. An example is given below.
- The attribute hierarchy is the hierarchy of attributes; this is used when one attribute is a generalization of another. For example, the attribute element-enhanced is a kind of element. In this case, element enhanced means that the element is not only present but is present in enhanced quantities. (Attribute hierarchies are particularly important in regard to managing negation. For example, declaring the feature “HasElement <silver> {absent}” conflicts with “HasEnhancedElement<silver>{present}”.
As a simple example, the following figure gives a portion of a value hierarchy for one conceptualization of sizes of things. The human-range is the range of sizes that humans can have a direct experience of. This ranges in size from the size of a grain of sand that someone can hold in their hand to the size of a mountain that someone can climb. We will use this hierarchy in subsequent examples.
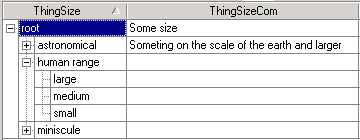
Intuitively, the “true” value of an instance feature is one of the leaves of the hierarchy, but we may not know or care which value is the true value. For example, the true value may be large, but for an instance we may not know it is large, we may only know it is in the human range. For a model we may only care that the value is in the human range, and not care if it is large, medium or small. The homo-hierarchy thus lets us specify the value at a higher level of abstraction.
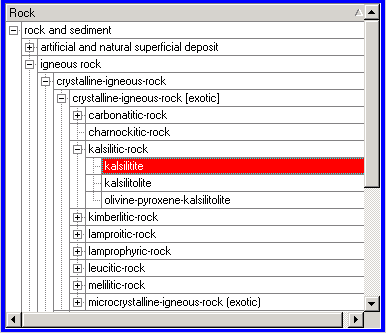
In the geological domain, the following figure shows part of the value hierarchy for rocks. Kalsilitite is a kind of kalsilitic rock, which is, in turn, a kind of crystalline igneous rock [exotic].
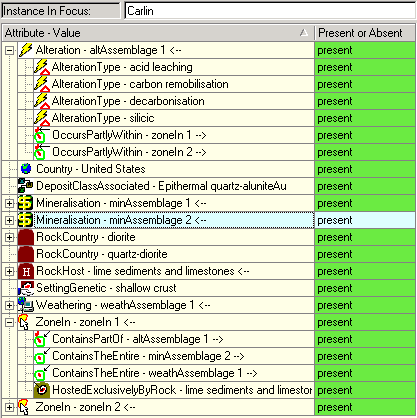
An example of the semantic network is the following description of the Carlin gold deposit. This specifies the attributes and values for the various features that define this instance. This hierarchically describes the components of the deposit. There are two mineralisation assemblages in this deposit, two zones and one alteration assemblage; one of the alteration assemblages and one of the zones are expanded in this figure:
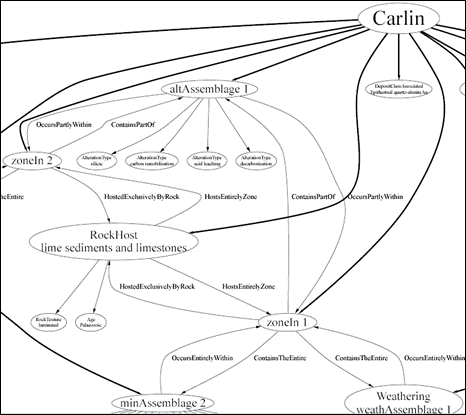
It is often more useful to view the semantic network graphically as in following portion of a GraphViz diagram from MineMatch:
Describing Instances
To describe an instance (e.g., a mineral deposit), we need to specify the attributes and the values of the attributes. For each attribute-value pair we specify whether the value is present or absent. Using a semantic network, we can give a hierarchical decomposition of the instance.
The instances are entities. Usually the instances that we want to describe are structured. These entities have properties of their own, but they can also contain subparts, each of which is an entity. The semantic network lets us organise this hierarchy of entities and their parts.
We sometime need to reify---give a name to---parts that we want to refer to individually. In the Carlin gold deposit, we gave arbitrary names (zoneIn 1 and zoneIn 2) to the two zones of the mine. These two zones have different properties. The actual name used does not matter and the program doesn’t attach any importance to the name (ie: in matching).
Certain attributes allow us to inherit other attributes. For example, in the Carlin mine, Zone1 contains part of altAssemblage1 and so inherits the attribute AlterationType and the corresponding values acid leaching, carbon remobilization, etc. For each attribute we specify how other attributes can be inherited through it.
Matching, Missing Values and the Homo-hierarchy
Missing values have different meanings for models and instances:
- For models, a missing value means we don’t care what value it is.
- For instances, a missing value means we don’t know what value it is.
When choosing values from a homo-hierarchy, assigning a non-leaf node raises similar issues:
- For models, a value that is not a leaf in the homo-hierarchy means we don’t care which leaf descendant the value really is for it to be a match.
- For instances, a value that is not a leaf in the homo-hierarchy means we don’t know which leaf descendent the value really is.
For example, in the ThingSize hierarchy above, when a model specifies that the size in the human range, it means that it should match any size within this range. When an instance specifies that the size is in the human range, it means that we don’t know what its actual size is; just that the actual size is in the human range.
This distinction is important when we are matching models to models, models to instances and instances to instances. First we will discuss the issue of how the homo-hierarchy interacts with the matching in isolation and then we will relate it to the semantic network and to the surprise measures.
There is a symmetry between how we treat missing values in the hetero-hierarchy and the position in the homo-hierarchy. A missing value can be equivalent to having a value that is the top of the homo-hierarchy, the root of the hierarchy, which represents “any value” (particularly when the silence implies absence assumption - discussed below - is in effect).
An important feature of any intelligent system is the ability to explain matches. In MineMatch when you double click on a match or a conflict it explains why there is a match or a conflict.
Model-Instance matching
The most intuitive matching is between models and instances. A perfect match is when we know that the instance is an instance of the model. We need to consider all of the cases where the values for some attribute for the models and instances are specified or not, as well as when the values are hierarchically related or not.
The following table presents examples of all of the cases in context of the size hierarchy:
|
# |
Model |
Instance |
Match |
Comments |
|
1 |
Green |
Green |
Perfect match |
The size isn’t specified for either |
|
2 |
Green |
Large Green |
Perfect match (*) |
The size doesn’t matter for the model |
|
3 |
Large Green |
Green |
Non-perfect match |
The instance may or may not be large; we don’t know |
|
4 |
Large Green |
Miniscule Green |
No Match |
The instance isn’t large. |
|
5 |
Large
Green |
Human-range Green |
Non-perfect match |
The instance may or may not be large; we don’t know. This is a better match than example #3 as the instance is more specific. |
|
6 |
Human-range Green |
Large
Green |
Perfect Match (*) |
The model doesn’t care as long as the value is in the human range, which large is. |
So, in general, a model feature matches any instance feature with a value equal or lower in the hierarchy. A model value has a partial match with an instance value higher in the hierarchy or where the value isn’t specified. If the values are not above or below each other in the hierarchy, there is no match.
(*) There is a subtle issue when the model doesn’t specify a value that the instance does. The model would be a better match if it did specify a value that matches the instance attribute value. This is important when we are comparing an instance with multiple models. We don’t always want the most general model (the one that specifies the fewest attributes) to be better than the model that is more predictive (even though the latter is necessarily less likely). Thus it is reasonable to give penalties for information outside of the scope of the model. The MineMatch matcher offers an option to “disable penalties for information outside the scope of the model”. In some sense the penalties should be seen as penalties for the model rather than for the instance. Thus we would expect to disable penalties when ranking a model against multiple instances, but enable the penalties when ranking an instance against multiple models.
For the non-perfect match we currently divide the score of a perfect match by one plus the depth difference. So if the instance value is one level higher than the model value in the homo-hierarchy, the score is the perfect match score is divided by two. If it is two levels higher, we divide by three. The details of the scoring are given in the appendices.
Instance-Instance matching
The case of matching one instance to another is technically the simplest (as we don’t have the surprise measures in the instances) but is conceptually more difficult than the previous case.
To match two instances, we treat one of the instances, the focus instance, as a model. We treat the other instance, the target or the match object as an instance. The focus instance is the query in MineMatch and LegendBurster. The match then proceeds as in the model-instance matching above. Note that this means that instance-instance matching is asymmetric; you may get different answers depending on which is the focus instance and which is the target.
Model-Model matching
Similarly, when we compare models to models, we treat one, the focus model, as a model and the other, the match object, as an instance. The matching proceeds as in the model-instance matching above. Intuitively, we are asking the question as to whether the second model would match the first if it were an instance. Again this means that model-model matching is asymmetric. The model-model matching is also complicated by the need to compare the surprise measures.
Matching and the Semantic Network
The matching also needs to interact with the semantic network. This is complicated because the attributes used in the semantic network are arbitrary and not predefined, unlike the uniform “AKO” relationships of the value hierarchy.
There are five types of attributes:
· Normal attributes are those whose value is part of a homo-hierarchy. For example, the attribute size that has a value in the ThingSize homo-hierarchy. Some values are entities and some are not; a value is an entity if it can have other attributes. Whether a value can have other attributes (and what they are) is defined in the ontology. We say that the attribute is an entity if all of the values for the attribute can themselves have attributes.
· Free Text attributes have values that are arbitrary text, which are not used during matching (such as a mine’s name).
· Free Numeric attributes have value that are numbers or thresholds, such as “> 2.3”. These can be used during matching.
· Reified attributes are effectively entities, given an arbitrary name, which represent a collection of attributes. For example, ZoneIn can have values ZoneIn1, ZoneIn2, etc., where the name plays no semantic role.
· Referring attributes are those whose value is an already existing entity; either a normal attribute or a reified attribute.
When evaluating the match between an instance and a model (or an instance and an instance or a model and an instance), one of them is the in focus object and the other is the target object. We will match the in focus and the target object recursively, considering the structure of each of them.
Given an in focus object and a target object, we carry out the following comparison procedure that returns a numerical score for the comparison. We consider each attribute in turn.
- If there is no attribute for one of the objects and an attribute for the other, there is a penalty depending on the way the user decided to handle missing values (as described above).
- If they both have a single value for the attribute:
- For
- If they are Reified or they match according to the previous step, then we recursively conduct comparisons at the next level down in the description hierarchy.
- If they have multiple values for the same attribute, we try out each pair as above. We consider the pair with the highest score, then, on the remaining pairs we again consider the pairs with the highest scores and so on, till we have paired the values from the in focus and target objects. The score is then the sum of the scores of the pairs plus a penalty for the non-matching values if there are any, as in the first case.
This procedure needs to be complicated because we can’t assume that the model and the instance are defined at the same level of abstraction. For example, a model may be described in terms of a number of zones whereas the instance isn’t. Alternatively, an instance may be described in terms of a number of zones whereas the model isn’t. To be able to manage such cases, we need to inherit the values upwards in the semantic network. For example, if a mine contains an alteration zone that contains quartz, then the mine contains quartz. Sometimes we need to change the attribute name as we inherit upwards; for example, if an internal alteration zone contains quartz, then the mine contains quartz, but we want to maintain the information that this quartz is different from other quartz that is present in an external zone. We would thus inherit the former up using the alterationMineralInternal attribute, and the latter with alterationMineralExternal attribute.
The matching between the different names that are inherited upwards is made possible because of the attribute hierarchy. Just as we may have hierarchies of values, we can also have hierarchies of attributes. The following shows a hierarchy of attributes for when elements are present.
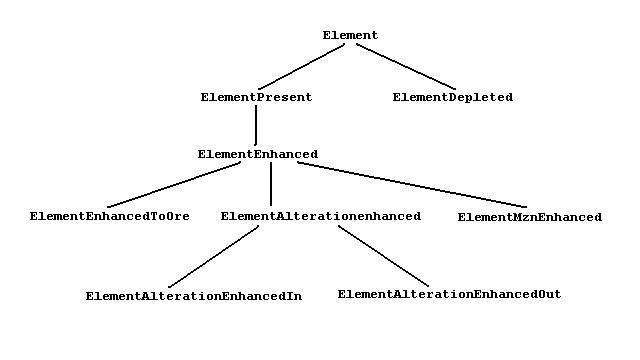
We use the same model-instance matching for attributes as we did for values. For example, if the model required elementEnhanced quartz, then it would match when the instance contains alterationMineralInternal quartz. When the model requires alterationMineralInternal, there is a non-perfect match when the instance has mineralEnhanced quartz.
Matching Examples
The following example illustrates some features of the comparison process.
The illustration below presents a MineMatch screen showing an instance called “Simple Instance”, and a model called “Simple Model”.
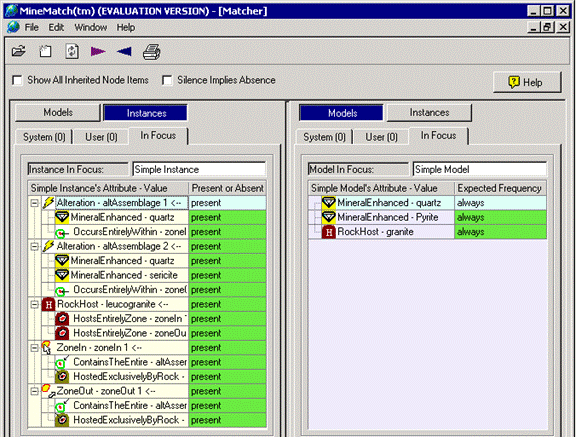
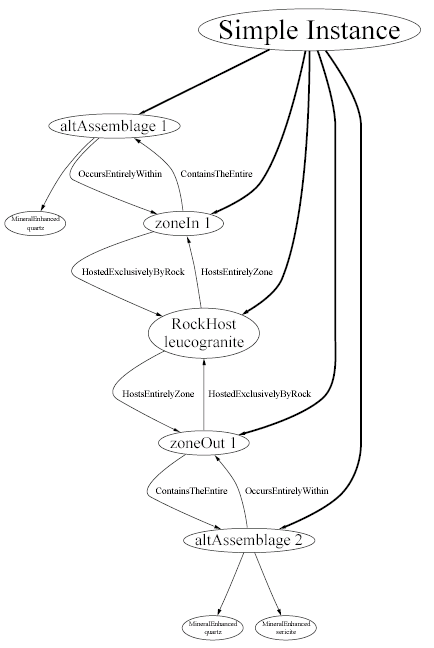
The instance contains two Alteration Assemblages, one ZoneIn, one ZoneOut, and a HostRock.
A diagrammatic representation of this description, drawn by the MineMatch system, is shown overleaf.
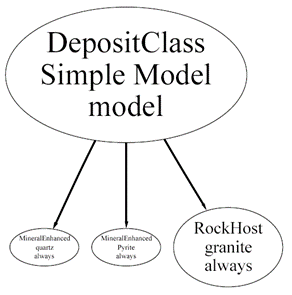
The model has two Minerals Enhanced, ‘quartz’ and ‘pyrite’, and a Host Rock ‘granite’.
This is a diagram of the model:
After we compare the model with the instance, we obtain the following result:
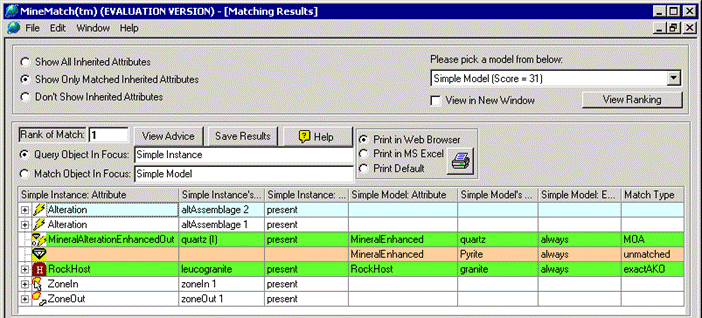
The comparison result shows that there is a match between the RockHost leucogranite in the instance and the RockHost granite in the model, and classifies it with the match type exactAKO. This is called an exactAKO match because leucogranite is a kind of granite.
Notice that the instance inherited the feature MineralAlerationEnhancedOut – quartz, which matches with the feature MineralEnhanced – quartz in the model. This match is classified as MOA (“Matched on Attribute”) because the attribute MineralAlternationEnhancedOut is a kind of MineralEnhanced.
Part 2: Practice
Introduction
MineMatch and LegendBurster measure similarity with a score calculated from the matching and conflicting features in any two descriptions being compared. The score calculated has a potential maximum equal to the score which results from comparing the in focus object with itself. An approximate minimum score can be determined by calculating the score which would be received by a description which conflicted with the in focus description in every possible way. The resulting value is only approximate, as unlimited “excess” information about the matched object may increase its penalties in an unlimited manner.
Both systems can report either the raw scores, or the scores normalized to the range 0 to 100, where 0 is a “perfect mismatch”, and 100 is a perfect match.
How Scores (Penalties and Rewards) are Calculated
The term ‘penalty’ means a score for a mismatch, i.e. how bad the mismatch is; while the term ‘reward’ means a score for a match, i.e. how good a match is. An ‘always’ match will have a higher reward than a ‘usually’ match, and a ‘usually’ match will have a much higher reward than a ‘sometimes’. Similarly, a ‘never’ mismatch will have a higher penalty than a ‘rarely’ mismatch. Matches and mismatches over a ‘sometimes’ frequency may, or may not, generate scores, as explained in the sections below.
We will explain how penalties and rewards are assigned in the most intuitive matching, which is between models and instances. In the comparison scenario between an instance and a set of instances, the query instance is considered as the model in the comparison process. In the comparison scenario between a model and a set of models, the query model is considered as the model, and the set of models is considered as a set of instances in the comparison process. Thus in all comparison scenarios, penalties and rewards are assigned in a similar fashion to the model to instance comparison
Model to Instance Comparing
When we are comparing the features of a model and an instance, the expected frequencies of the model and the presence in or absence from the instance determine what score is given for features that match or conflict.
There two main contexts to consider:
- The attribute under consideration appears in both the model and instance descriptions
- The attribute under consideration appears in either the model or the instance description
Different situations can arise in each of these contexts, as explained below.
Model and Instance have the same attribute
Rewards are given when, for a particular attribute, both model and instance have the same value, and their frequencies are not in conflict. If their frequencies are in conflict, then penalties are assigned and comparison is not continued to any lower levels of description. The following chart illustrates these cases:
|
Model feature’s
frequency Instance feature’s presence |
must have |
always |
usually |
sometimes, <other values> = never |
sometimes, <other values> = possible |
rarely |
never |
must exclude |
|
present (LegendB.) |
+10000 |
+10000 |
+9000 |
+1000 |
+100 |
-1000 |
-10000 |
FAIL |
|
present (MineMatch[1]) |
+10000 |
+10000 |
+9000 |
+4000 |
+2000 |
-1000 |
-10000 |
FAIL |
|
absent |
FAIL |
-10000 |
-1000 |
0 |
0 |
0 |
0 |
0 |
*** note: the term <other values> means whether other values are possible for the attribute associated with a feature.
Penalties for
Unmatched Instance Values
This situation arises when, for a particular attribute which has at least one value in the model, one or more unmatched values occur in the instance.
If the Model has explicitly declared a feature of the same attribute with <other values> = never or Silence Implies Absence is true, we will assign a penalty of 10000 for any unmatched instance feature.
Else if the Model has explicitly declared a feature of the same attribute with <other values> = sometimes or Silence Implies Absence is false, we will assign no penalty or reward for any unmatched instance feature.
Penalties for
Unmatched Model Values (Model in focus)
This situation arises when a model feature has not been matched with any of the instance’s features, whose attributes are the same as the model feature’s. For example, if a model has feature <Element, Pb, always>, and the instance has features {<Element, Au, present>, <Element, Cu, present>}, then the model value Pb is considered unmatched.
How they are scored depends on whether the assumption that silence implies absence is true and whether the model has explicitly declared <other values> = never or possible for that same attribute. If silence implies absence is true and the model does not explicitly declare <other values> are possible for that attribute, or the model explicitly declares that <other values> = never for that attribute, heavy penalties will be incurred for unmatched model features whose frequencies are always or usually. Otherwise, low penalties will be incurred for unmatched model features whose frequencies are always or usually. The following chart illustrates these cases:
|
expected frequency Silence Implies Absence status |
must have |
always |
usually |
sometimes |
rarely |
never |
must exclude |
|
True and Model does not have a feature that declares for this attribute: <other values> = possible OR Model has a feature that explicitly declares for this attribute: <other values> = never |
FAIL |
-10000 |
-9000 |
0 |
0 |
0 |
0 |
|
False and Model does not have a feature that declares for this attribute: <other values> = never OR Model has a feature that explicitly declares for this attribute: <other values> = possible |
FAIL |
-100 |
-10 |
0 |
0 |
0 |
0 |
*** note: FAIL means that the worst score is applied to the comparison
When Model and Instance have “disjoint” attributes
Penalties for
Extra Model Features (Model in focus)
This situation arises when a model feature exists for an attribute which is not mentioned in the instance.
|
expected
frequency Silence Implies Absence status |
must have |
always |
usually |
sometimes |
rarely |
never |
must exclude |
|
True |
FAIL |
-10000 |
-9000 |
0 |
0 |
0 |
0 |
|
False |
FAIL |
-100 |
-10 |
0 |
0 |
0 |
0 |
*** note: FAIL means that the worst score is applied to the comparison
Penalties for
Extra Instance Features (Model in focus)
This situation arises when an instance feature exists for an attribute which is not mentioned in the model.
A penalty of one is assigned to each of the extra instance feature. In LegendBurster, if Disabled Penalties is true, then no penalties will be assigned to extra instance features.
Comparison at Sub-Levels of Description
When we consider lower levels in a description, we must take into account the frequency that is associated with the sub-entity (or sub-part) being described, and accumulate rewards and penalties in a manner appropriate to the frequency. This entails the incorporation of scores least attenuated for entities always and usually expected, attenuated for entities expected sometimes, and most attenuated for entities expected rarely. As explained in the first section of this document, match scoring does not continue down through a conflicting feature, or matching absent (negated) features.
Case 1: Model Sub-Entity’s frequency = ‘always’
If the sub-entity’s frequency is ‘always’, the penalties and rewards collected downwards will remain unchanged.
Case 2: Model Sub-Entity’s frequency = ‘usually’
If the sub-entity’s frequency is ‘usually’, the rewards collected downwards will be multiplied by a factor of 0.9, and the penalties will be multiplied by a factor of 0.1.
Case 3: Model Sub-Entity’s frequency = ‘sometimes’
If Silence implies Absence is true and the model does not have a feature that declares for the considered attribute that <other values> = possible
OR
if the model has a feature that explicitly declares for the considered attribute that <other values> = never
THEN the rewards collected will be multiplied by a factor of 0.1 for LegendBurster and 0.4 for MineMatch[2] and penalties will be ignored.
Otherwise all rewards will be multiplied by 0.1 (0.2 for MineMatch) and penalties will be ignored.
Case 4: Model Sub-Entity’s frequency = ‘rarely’
Penalties will be equal to the rewards multiplied by 0.1. There will be no rewards.
Case 5: Model Sub-Entity’s frequency = ‘never’
Penalties will be equal to the rewards and there will be no rewards.
Case 6: Model Sub-Entity’s frequency = ‘must have’
If the sub-entity’s frequency is ‘must have’, it will be treated as an ‘always’.
Case 7: Model Sub-Entity’s frequency = ‘must exclude’
If the sub-entity’s frequency is ‘must exclude’, penalty and reward calculations are ignored, and the object is given the minimum possible score.
Match Types
MineMatch and LegendBurster record the types of matches or mismatches recognized during a comparison operation, and show these in their comparison reports.
The different types of matches and mismatches are listed below:
Matches
|
exact |
the instance feature’s value is the same as the model feature’s value, and their frequencies are not in conflict |
|
exactNumeric |
the instance feature’s numeric value is the same as the model feature’s numeric value, and their frequencies are not in conflict |
|
exactAKO |
the instance feature’s value is a kind of the model feature’s value, and their frequencies are not in conflict |
|
partialAKO |
the model feature’s value is a kind of the instance feature’s value, and their frequencies are not in conflict |
|
partial |
(only applies to Reified features) the instance feature’s value is the same as the model feature’s value, and some of their subparts also matches |
|
MOA |
match of attributes where one attribute is a kind of the other, and the match type of their values are either exact, exactNumeric, or exactAKO |
Conflicts
|
exactFreq |
the instance feature’s value is the same as the model feature’s value, but their frequencies are in conflict |
|
exactFreqAKO |
the instance feature’s value is a kind of the model feature’s value, and their frequencies are in conflict |
|
partialAKOFreq |
the model feature’s value is a kind of the instance feature’s value, and their frequencies are in conflict |
|
mismatchExtra |
the instance feature’s value is not a match or mismatch with any of the model’s features with the same attribute |
|
unmatched |
the model feature has not been matched |
|
conflictAtt |
match of attributes where one attribute is in conflict with the other, and the match type of their values are either exact, exactNumeric, or exactAKO |
Comparison Examples
Case 1:
ý Silence Implies Absence
þ Disable Penalties for Information Outside of Scope
ý Explicit [attribute, <other values>, never] specified for a feature
ý Explicit [attribute, <other values>, always/usually/sometimes/rarely] specified for a feature
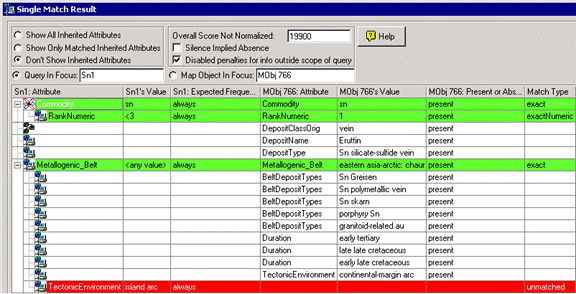
Analysis of scores:
The query Sn1’s [Commodity, Sn, always] is matched exactly by MObj 766’s [Commodity, Sn, present], and thus receives a reward of 10000.
Further, Commodity Sn’s [RankNumeric, < 3, always] is matched exactly by MObj 766’s [RankNumeric, 1, present], and again receives a reward of 10000.
The query Sn1’s [Metallogenic_Belt, <any value>, always] is matched exactly by MObj 766’s [Metallogenic_Belt, eastern asia-artic: chaun, present], but does not receive any reward because the query’s value is <any value>.
However, there is a penalty of 100 assigned to an unmatched feature [TectonicEnvironment, island arc, always] in the query. A penalty of 100 is assigned because the feature’s frequency is always, and Silence Implies Absence is false for the comparison.
Thus, the overall score is 10000 + 10000 – 100 = 19900.
Case 2:
þ Silence Implies Absence
þ Disable Penalties for Information Outside of Scope
ý Explicit [attribute, <other values>, never] specified for a feature
ý Explicit [attribute, <other values>, always/usually/sometimes/rarely]
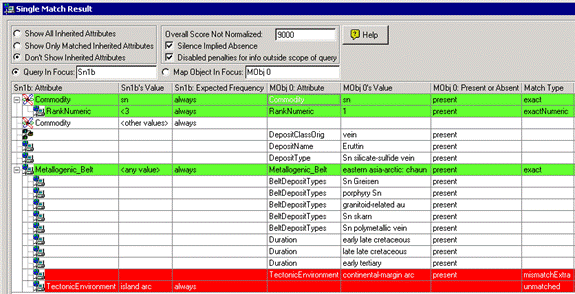
Analysis of scores:
The query Sn1’s [Commodity, Sn, always] is matched exactly by MObj 766’s [Commodity, Sn, present], and thus receives a reward of 10000.
Further, Commodity Sn’s [RankNumeric, < 3, always] is matched exactly by MObj 766’s [RankNumeric, 1, present], and again receives a reward of 10000.
The query Sn1’s [Metallogenic_Belt, <any value>, always] is matched exactly by MObj 766’s [Metallogenic_Belt, eastern asia-artic: chaun, present], but does not receive any reward because the query’s value is <any value>.
However, there is a penalty of 10000 assigned to an unmatched feature [TectonicEnvironment, island arc, always] of the query. A penalty of 10000 is assigned because the feature’s frequency is always, and Silence Implies Absence is true for the comparison.
Moreover, because Silence Implies Absence is true, MObj 766’s unmatched feature [TectonicEnvironment, continental-margin arc, always] gets a penalty of 10000.
Thus, the overall score is 10000 + 10000 – 10000 – 10000 = 0.
Case 3:
þ Silence Implies Absence
þ Disable Penalties for Information Outside of Scope
ý Explicit [attribute, <other values>, never] specified for a feature
þ Explicit [TectonicEnvironment, <other values>, sometimes] specified
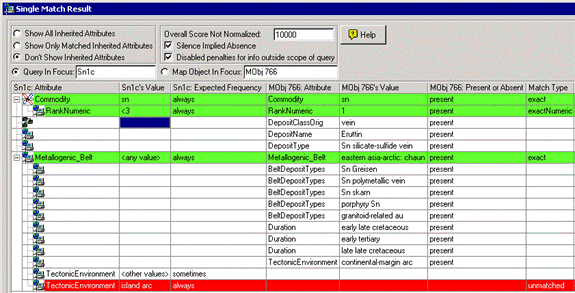
Analysis of scores: (Refer to diagram above)
The query Sn1’s [Commodity, Sn, always] is matched exactly by MObj 766’s [Commodity, Sn, present], and thus receives a reward of 10000.
Further, Commodity Sn’s [RankNumeric, < 3, always] is matched exactly by MObj 766’s [RankNumeric, 1, present], and again receives a reward of 10000.
The query Sn1’s [Metallogenic_Belt, <any value>, always] is matched exactly by MObj 766’s [Metallogenic_Belt, eastern asia-artic: chaun, present], but does not receive any reward because the query’s value is <any value>.
However, there is a penalty of 10000 assigned to an unmatched feature [TectonicEnvironment, island arc, always] of the query. A penalty of 10000 is assigned because the feature’s frequency is always, and Silence Implies Absence is true for the comparison.
Although Silence Implies Absence is true, MObj 766’s extra feature [TectonicEnvironment, continental-margin arc, always] does not get a penalty as in Case 2 because the query Sn1 specifies the feature [TectonicEnvironment, <other values>, sometimes]. The feature [TectonicEnvironment, <other values>, sometimes] indicates that other values are possible for TectonicEnvironment, and thus no penalties should be incurred for the corresponding unmatched features mentioned in MObj 766.
Thus, the overall score is 10000 + 10000 – 10000 = 10000.